p106在ubuntu20.04下驱动及cuda的安装
p106在ubuntu20.04下驱动及cuda的安装
驱动安装
安装相关依赖
sudo apt-get update
sudo apt-get install python3-pip
sudo apt-get install cmake gcc build-essential 查看可以安装的驱动
sudo ubuntu-drivers devices如果提示没有找到ubuntu-drivers命令,尝试安装
sudo apt-get install ubuntu-drivers-common直接安装
sudo apt install nvidia-driver-525-server遇到的问题
把显卡插上去之后,没有网络,发现是dhcp没有启动,执行dhcp 网卡名称 恢复,将该命令添加到rc.local解决问题
rc.local添加开机自启动脚本 - 笔记 (hushanwei.top)
CUDA安装
以cuda12.0为例
先关闭图形化界面
systemctl isolate multi-user.target会提示重启,重启之后输入
modprobe -r nvidia-drm安装完成后再打开图形化界面
sudo systemctl start graphical.target 搜索cuda12.0,获取下载地址
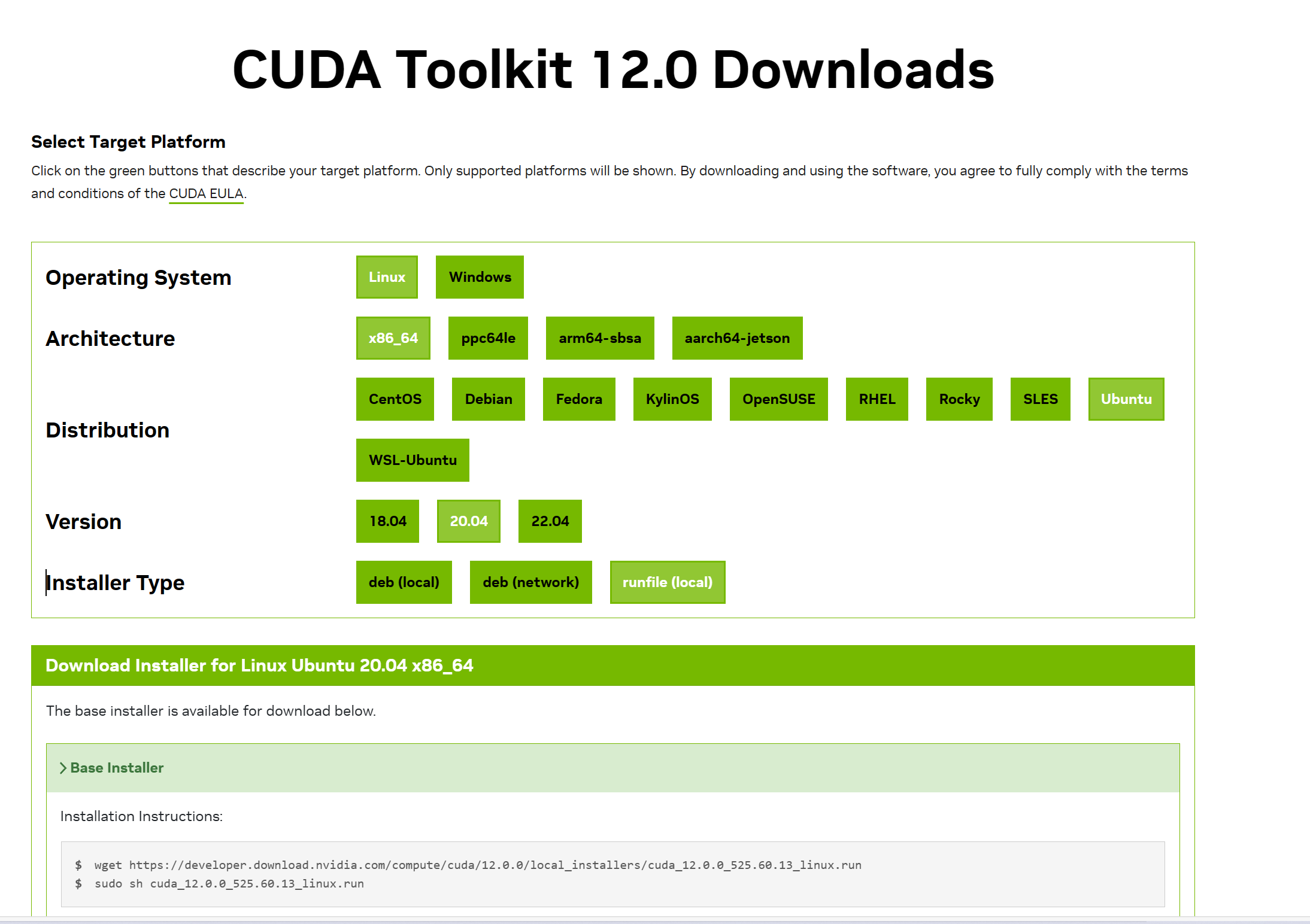 按照官网的命令执行
按照官网的命令执行
因为已经安装了驱动,所以这一步取消驱动的安装
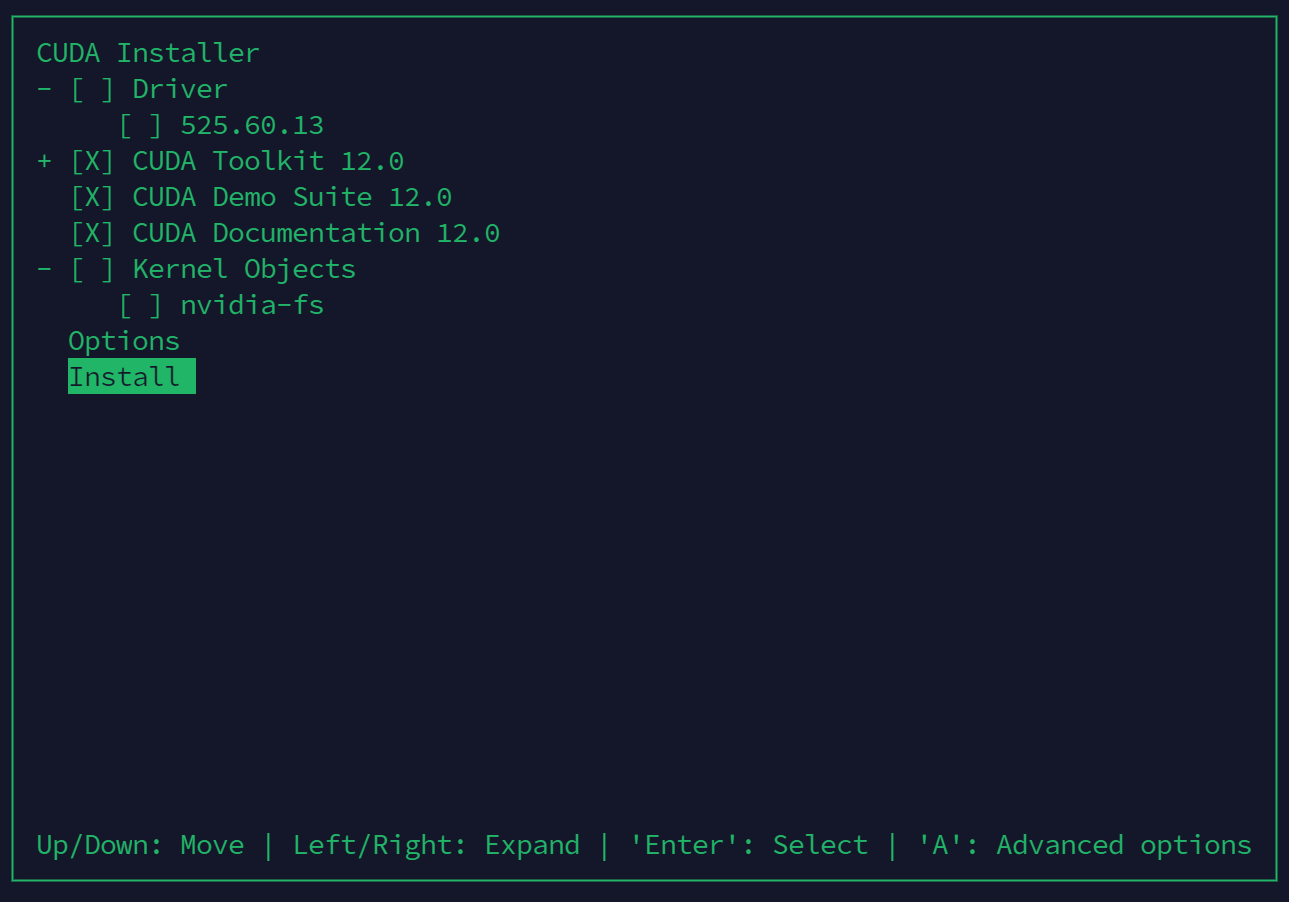 安装完成后,根据提示将cuda路径添加到~/.bashrc或者~/.profile中
安装完成后,根据提示将cuda路径添加到~/.bashrc或者~/.profile中
sudo nano ~/.bashrcexport PATH=/usr/local/cuda-12.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-12.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
#其他版本将版本号更改即可source ~/.bashrc验证
nvcc -V输出
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Mon_Oct_24_19:12:58_PDT_2022
Cuda compilation tools, release 12.0, V12.0.76
Build cuda_12.0.r12.0/compiler.31968024_0CUDA驱动的卸载
进入cd /usr/local/cuda-12.2/bin 执行cuda-uninstaller
测试CUDA是否可用
使用pytorch
先安装pytorch
pytorch安装 - 笔记 (hushanwei.top)
执行
import torch
print('CUDA版本:',torch.version.cuda)
print('Pytorch版本:',torch.__version__)
print('显卡是否可用:','可用' if(torch.cuda.is_available()) else '不可用')
print('显卡数量:',torch.cuda.device_count())
print('是否支持BF16数字格式:','支持' if (torch.cuda.is_bf16_supported()) else '不支持')
print('当前显卡型号:',torch.cuda.get_device_name())
print('当前显卡的CUDA算力:',torch.cuda.get_device_capability())
print('当前显卡的总显存:',torch.cuda.get_device_properties(0).total_memory/1024/1024/1024,'GB')
print('是否支持TensorCore:','支持' if (torch.cuda.get_device_properties(0).major >= 7) else '不支持')
print('当前显卡的显存使用率:',torch.cuda.memory_allocated(0)/torch.cuda.get_device_properties(0).total_memory*100,'%')输出
CUDA版本: 12.1
Pytorch版本: 2.1.0+cu121
显卡是否可用: 可用
显卡数量: 1
是否支持BF16数字格式: 不支持
当前显卡型号: NVIDIA P106-100
当前显卡的CUDA算力: (6, 1)
当前显卡的总显存: 5.93243408203125 GB
是否支持TensorCore: 不支持
当前显卡的显存使用率: 0.0 %或者使用黄狗给的测试示例
项目地址
https://github.com/NVIDIA/cuda-samples
选择适合自己cuda版本的下载
适用于12.0的示例https://vip.123pan.cn/1815661672/%E7%9B%B4%E9%93%BE/cuda-samples-12.0.tar.gz
在Sample目录中有多个测试示例
hu@hu:~/cuda/cuda-samples-12.0/Samples$ ls
0_Introduction 1_Utilities 2_Concepts_and_Techniques 3_CUDA_Features 4_CUDA_Libraries 5_Domain_Specific 6_Performance依次是
0. Introduction
Basic CUDA samples for beginners that illustrate key concepts with using CUDA and CUDA runtime APIs.
1. Utilities
Utility samples that demonstrate how to query device capabilities and measure GPU/CPU bandwidth.
2. Concepts and Techniques
Samples that demonstrate CUDA related concepts and common problem solving techniques.
3. CUDA Features
Samples that demonstrate CUDA Features (Cooperative Groups, CUDA Dynamic Parallelism, CUDA Graphs etc).
4. CUDA Libraries
Samples that demonstrate how to use CUDA platform libraries (NPP, NVJPEG, NVGRAPH cuBLAS, cuFFT, cuSPARSE, cuSOLVER and cuRAND).
5. Domain Specific
Samples that are specific to domain (Graphics, Finance, Image Processing).
6. Performance
Samples that demonstrate performance optimization.
7. libNVVM
Samples that demonstrate the use of libNVVVM and NVVM IR.0. 简介
面向初学者的基本 CUDA 示例,说明使用 CUDA 和 CUDA 运行时 API 的关键概念。
1. 公用事业
演示如何查询设备功能和测量 GPU/CPU 带宽的实用程序示例。
2. 概念和技术
演示 CUDA 相关概念和常见问题解决技术的示例。
3.CUDA特性
演示 CUDA 功能的示例(协作组、CUDA 动态并行性、CUDA 图等)。
4.CUDA 库
演示如何使用 CUDA 平台库(NPP、NVJPEG、NVGRAPH cuBLAS、cuFFT、cuSPARSE、cuSOLVER 和 cuRAND)的示例。
5. 特定领域
特定于领域(图形、金融、图像处理)的示例。
6. 性能
展示性能优化的示例。
7.libNVVM
演示 libNVVVM 和 NVVM IR 用法的示例。例如想要测试矩阵乘法(需要先编译)
hu@hu:~/cuda/cuda-samples-12.0/Samples/0_Introduction/matrixMul$ cd /home/hu/cuda/cuda-samples-12.0/Samples/0_Introduction/matrixMul
hu@hu:~/cuda/cuda-samples-12.0/Samples/0_Introduction/matrixMul$ ls
Makefile matrixMul.cu matrixMul_vs2017.sln matrixMul_vs2019.sln matrixMul_vs2022.sln NsightEclipse.xml
matrixMul matrixMul.o matrixMul_vs2017.vcxproj matrixMul_vs2019.vcxproj matrixMul_vs2022.vcxproj README.md
hu@hu:~/cuda/cuda-samples-12.0/Samples/0_Introduction/matrixMul$ ./matrixMul
[Matrix Multiply Using CUDA] - Starting...
GPU Device 0: "Pascal" with compute capability 6.1
MatrixA(320,320), MatrixB(640,320)
Computing result using CUDA Kernel...
done
Performance= 411.88 GFlop/s, Time= 0.318 msec, Size= 131072000 Ops, WorkgroupSize= 1024 threads/block
Checking computed result for correctness: Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
License:
CC BY 4.0